Try Privatemode AI - the most advanced Confidential AI service.

Blog

Moritz Eckert
To run AI workloads at scale, enterprises are increasingly relying on the public cloud. In this context, data security and privacy can become key concerns. In essence, today, companies need to trust the cloud service provider (CSP) with their data and AI-related intellectual property.
And there are also other parties to trust, as AI services typically have several stakeholders. Consider for example the schematic AI pipeline below: the AI model, the training data, and both the code for training and inference are often provided by different stakeholders. All these stakeholders must trust each other and the CSP with their valuable (and possibly regulated) data or intellectual property.
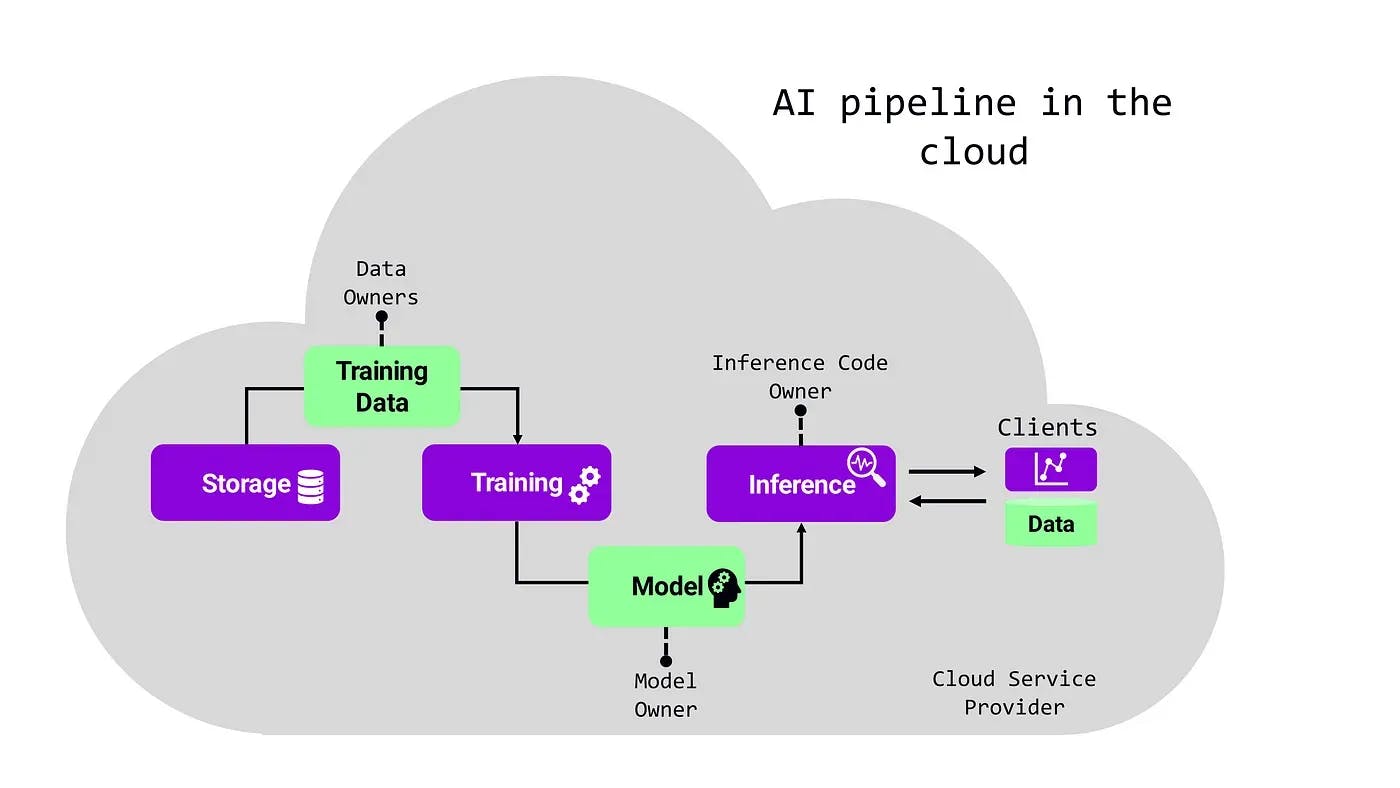
Confidential computing is a key technology that can solve these fundamental problems, as it enables the always-encrypted and verifiable processing of data. With it, businesses can collaborate and rely on the public cloud without losing control of their data or intellectual property. For more information refer to our post "Confidential Computing --- Basics, Benefits and Use Cases".
In this post, we will walk through the process of setting up a confidential AI inference service. We'll showcase a multi-stakeholder scenario including the CSP, model owner, inference service provider, and users.
For this, we'll use the open-source tools TensorFlow Serving, MarbleRun, and Graphene, which we introduce briefly now.
TensorFlow Serving (TF Serving) is one of the most popular frameworks for AI inference. TF Serving provides a consistent API for gRPC and HTTP, independent of the underlying model. It also provides an easy-to-use interface for updating and changing these models. TF Serving requires a Python execution environment.
Graphene is a framework for creating confidential applications. In essence, it allows one to run almost arbitrary software in an Intel SGX enclave (which is the hardware feature that enables confidential computing). Graphene supports running TF Serving in SGX enclaves. We are going to use their inference service enclave for this tutorial.
Kubernetes is the de-facto standard for orchestrating workloads in the cloud. The MarbleRun framework takes care of confidential computing-specific aspects in a Kubernetes cluster, including key and identity management and attestation. We wrote a separate blog post that introduces the specific challenges of confidential computing workloads in the cloud and how MarbleRun addresses them. In a nutshell, MarbleRun makes it easy to deploy, scale, and verify your SGX-based apps on Kubernetes. Think Istio/Consul/Linkerd for confidential computing.
The Scenario is the following: You would like to offer an AI inference service, e.g., as a SaaS offering, running on a public cloud. The model is provided by a third party. The third party does not necessarily like to give you or the CSP direct access to their model to protect their intellectual property. Similarly, you would like to ensure the integrity of your inference service as well as keep the input of your clients' data confidential.
To overcome these concerns, we run the inference service inside a confidential computing enclave using Graphene and Intel SGX. To that end, we deploy TF Serving using Graphene's example application. That way our TF Serving service is integrity protected and all data is always encrypted at all times. In the second step, we deploy our service with MarbleRun on a public cloud. MarbleRun lets us easily orchestrate the deployment of our confidential service and facilitates the process of managing access to the model owner's pre-trained model. It further simplifies all stakeholder verification and attestation processes.
The workflow looks like this:
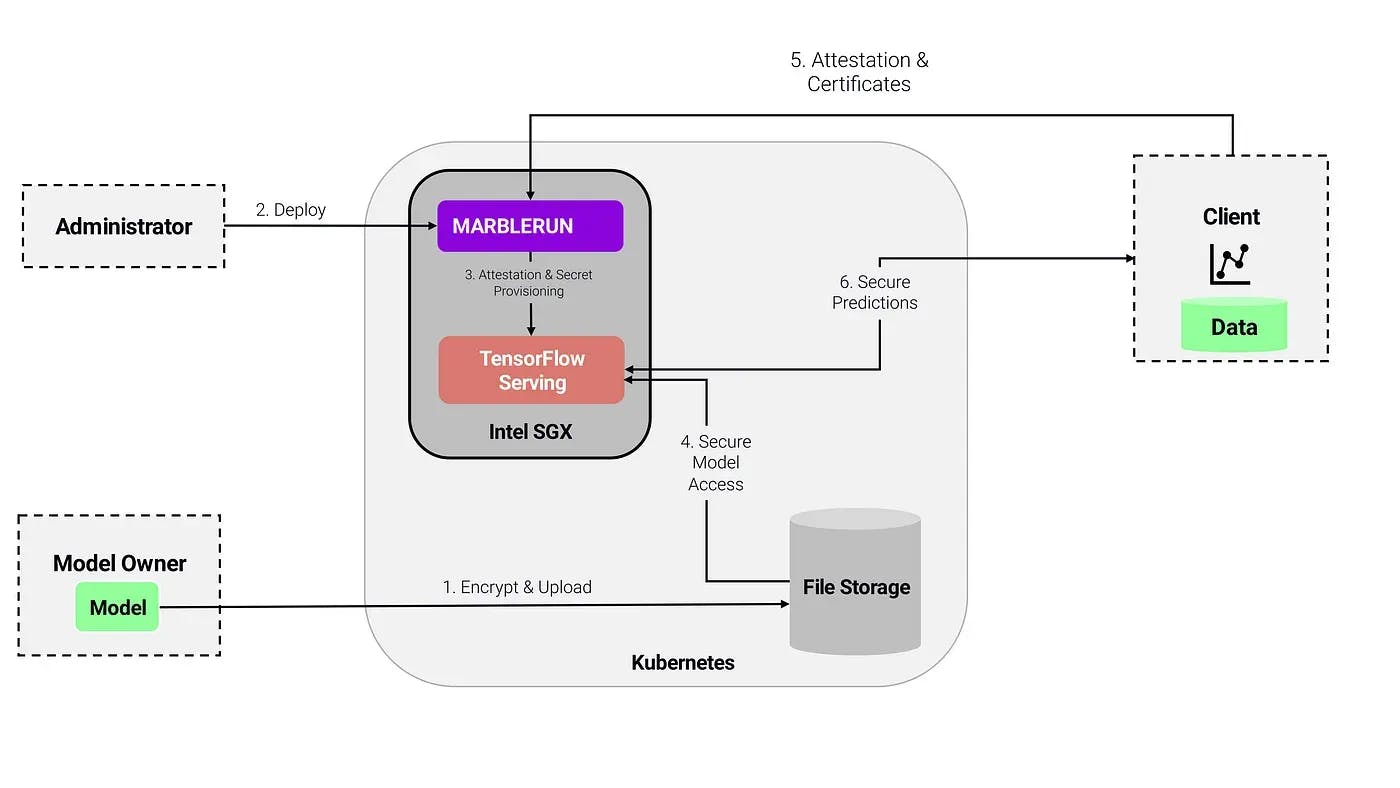
1\. The model owner encrypts the model and uploads the encrypted model to a cloud storage
2\. The administrator deploys MarbleRun with a manifest defining the topology and components of the confidential AI deployment
3\. The administrator deploys the confidential AI application.
4\. MarbleRun takes care of authentication and bootstrapping procedures.
5\. The model owner verifies the deployment via MarbleRun and uploads the encryption key securely to the TensorFlow Serving application via MarbleRun's secret distribution.
6\. The application can decrypt the model inside the enclave via the provisioned key.
7\. Clients can verify the deployment via MarbleRun and connect securely to the inference service, knowing that their data is only accessible inside the enclave and their predictions are made by the integrity-protected TensorFlow Serving application.
For a hands-on tutorial of this scenario check out our GitHub repository.
In this tutorial, we walked through a hands-on example of confidential inference. We demonstrated how a multi-stakeholder scenario can be organized with MarbleRun through a common manifest. For a production deployment, the next step would be to make the application scalable. Luckily, MarbleRun makes it easy to scale confidential workloads on K8s. Do let us know in the comments section if you'd like to read a tutorial on scaling the confidential inference app we discussed here.
Also, if you want to discuss confidential AI or other exciting confidential computing applications join our Discord or get in touch.
Author: Moritz Eckert






