Blog
A look at the open-source confidential computing landscape
Welcome back to our spotlight series that features interesting projects from the confidential computing open-source community. In this blog post, we're going to dive into Occlum and how its developer team optimized the project for the new generation of Intel SGX.
The mission of the Occlum project is to empower everyone to run every application inside secure enclaves. It makes running apps inside enclaves easy by allowing one to run unmodified programs inside enclaves with just a few simple commands. Occlum's command line tool (CLI) has two primary commands. The first one is the build command, which you can use to create an Occlum image and establish an enclave. The build command can take an untrusted user file system and turn it into an Occlum trusted image. By using the run command, you start an enclave, and the library OS will load the trusted image and start your program.
With Occlum, you only need to type some simple commands.
Let's talk a look at a hands-on example. You have a "Hello World" program and use GCC to compile it for Linux. The first command we use is like git init: the occlum init command is used to initialize the current folder in an Occlum context. After copying the program into the image directory, the previously mentioned build command builds the Occlum image as well as the enclave. Finally, you can use the command "occlum run" to run your program.
If you've read other articles from our blog, you might recognize the general approach from our EGo project. Did you also know that MarbleRun now officially supports Occlum? By combining the two, you can manage, scale, and verify confidential apps intuitively!
As many of you may have known, Intel has recently launched its third generation of the Xeon scalable processor family (formerly referred to as Ice Lake). This new generation also features some major changes to Intel SGX, the first being a relaxed threat model. The new SGX will target use cases where the physical environments are trusted, which is why it still offers full protection against cyber-attacks but only partially protects itself from physical attacks. This trade-off is what enables the second major feature: improved scalability. The new SGX is the first with a large enclave page cache, up to one terabytes of enclave memory and only minimal overhead of memory access inside the enclave. Additionally, it is implemented on a multi-socket platform, which opens up multi core computation for enclave programs.
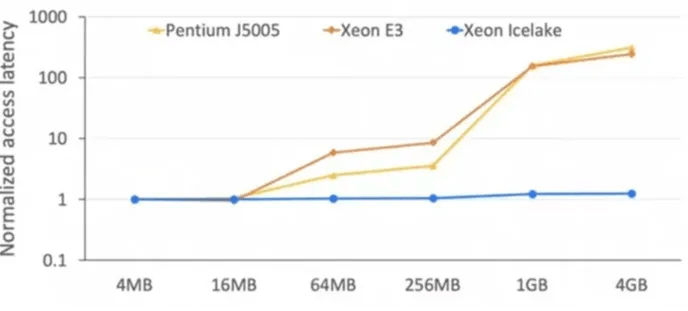
So far, the performance difference was benchmarked with Pentium Silver, Xeon E3 and Xeon Icelake CPUs. The Occlum team measured the overheads of SGX, which are enclave memory access, enclave dynamic memory management (EDMM), and enclave switching with various sizes of working memory. Overall, there was minimal overhead. While enclave switching is still a costly process, even this part of running enclaves was significantly improved.
Most developers who are working with library OSes on Intel SGX run into a common optimization problem: the high cost of enclave switching will lead to poor I/O performance of the LibOS. Most I/O operations in the LibOS trigger enclave switching, and the high cost of EDMM will lead to poor memory management performance of the LibOS. With the new generation of Intel SGX, some of these problems are remedied. Since the new processor offers several additional CPU cores, there is new potential for increased parallelism at the LibOS level. Also, since there is more enclave memory, performance may be increased by more aggressive data caching or memory pooling.
With these observation in mind, the Occlum team has started an overhaul of their LibOS called Next-Gen Occlum (NGO). The centrepiece of this re-architected version of Occlum is a new async-centric design with four levels: at the language level, the team plans to address the question of how to easily express complex async logic. Following this, they are looking into solving the problem of efficient scheduling of async code. On top of that, they have set their goal to perform async I/O with increased efficiency. With all of this, they plan to have the LibOS Kernel perform accelerated system calls. With the implementation of this design, the NGO project can deliver a close-to-native performance on some of the most OS-intensive workflows.

Language level
Before we go into more detail, let's look at the async-centric design. To keep it brief, asynchrony allows for increased parallelism inside the LibOS, which means increased performance. However, async programming is quite hard, which is why you normally wouldn't write async code. This is where Rust's async/await feature can help. Occlum is written in Rust, which is one of the first system program languages to natively support async/await functions. Async functions allow to perform time consuming operations by switching between tasks, for example by completing various tasks while it is waiting for an I/O input. Basically, async/await enables the user to write async code the sync way, without the need to write callbacks or event loops manually. Even more, the async/await feature in Rust is a zero-cost abstraction. In contrast to the async/await implementation in Javascript or C#, async/await in Rust has a much lower overhead.
Scheduling level
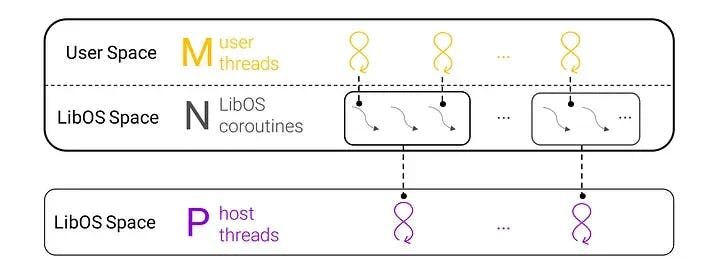
The core of NGO at the scheduling level lies within its coroutines. While there are many lightweight coroutines in the LibOS space, they are also fast to create and destroy and have very minimal memory footprints, which allows for several of them at the same time. A group of coroutines are mapped to a single host thread, so these coroutines can be scheduled completely inside the enclave without triggering enclave switching. Each coroutine can run either a LibOS task or user task: usually, each user task corresponds to user threads. User threads are preemptible, so the user's rights are preemptively scheduled and LibOS tasks are cooperatively scheduled. This allows for increased LibOS parallelism with only slight overhead.
I/O level
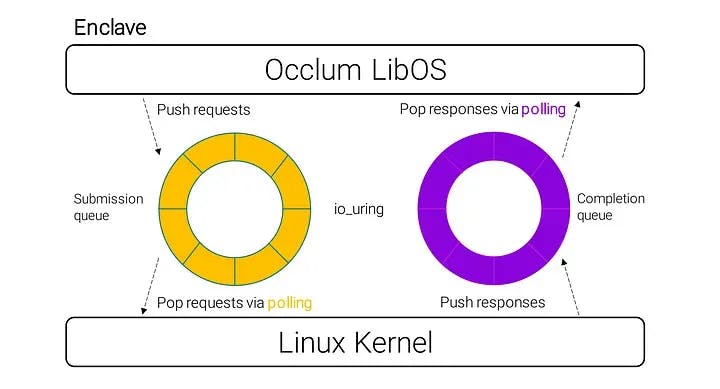
To facilitate async I/O, Linux's io_uring is introduced into the LibOS. Io_uring is a new I/O interface introduced in Linux kernel 5.1. As can be seen in the figure, io_uring allows for submission of I/O requests just by pushing the request into a submission queue, which is a ring buffer shared between the user space and the Linux kernel. Once the Linux kernel has completed the I/O operation, the results can be received by polling the completion queue. This process is extremely fast.
Kernel level
There are two classes of async techniques in the NGO project that were employed to speed up user calls, the first being eager execution. With eager execution, one can perform time consuming operations before the system call requests them. When the system calls arrive, the results are expected to be ready and can be returned to the user immediately. Traditionally, a LibOS syscall would require waiting for enclave switching and I/O processes. While regular switchless techniques might skip the enclave switching, they would still require the Linux I/O to be finished before the LibOS returns the system call. With the async approach of Occlum, the LibOS syscall can immediately accept returns without asking the Linux kernel to do any I/O. This is because it can do the async accept before the accept LibOS syscall even comes. This way, eager execution reduces the accept latency. This also applies to the read system calls in a comparable manner, which can be carried out by just using the receive buffers.
The next class of the async technique is promised execution. Basically, promised execution can delay the execution of time-consuming operations, so that the system calls can be returned immediately while keeping the original synchronous semantics of the system calls. For example, for the write LibOS syscall, the LibOS can store the user data into the page cache and choose to flush the dirty pages inside the page cache, so the write to files operation can be delayed. Promised execution can not only accelerate I/O but also speed up memory management, which is great news for the costly edmm inside enclaves.
With the ongoing development of confidential computing projects such as Occlum, confidential computing is reaching new levels of scalability and performance with minimal overhead. It is only a matter of time until confidential computing applications approach a level of usability close to common applications.
If you're interested in more details, visit the Github repository or the Occlum project homepage. Occlum is released by Ant Financial under BSD License. Full copyright information can be found here.
This blog post was delivered as a talk by Hongliang Tian (System Architect, Ant Group) at the Open Confidential Computing Conference 2021. You can watch the full recording on YouTube.








